Programming: Data Structures
Programming: Data Structures
Computers deal with a lot of data. Take a minute to think about how many social media accounts you have and how much each one knows about you. At first Shmoop wasn't really into the whole "share your entire life with Facebook" thing, but before we knew it, we'd liked our favorite brand of
- clothes
- shampoo
- pizza
- ice cream
- toothpaste
- self-adhesive bandage
which basically describes our entire day.
With all that data, companies and people want to pull out important information for science and marketing type things. It isn't Big Brother (well, maybe a little) so much as using the information we're willing to share.
But programmers need ways to easily store and access that information (for science?), because having billions of variables just won't cut it.
That's where data structures come in. Data structures are structures that—you guessed it—hold data. They come in many different flavors. We're only going to cover a couple to give you a sense of the different types of structures.
Lists
Lists don't really exist in any programming language: they're purely conceptual. That way, we don't need to worry about implementation. All we need to know is that lists hold the elements and we can access them by index or from grabbing the first or last element.
They can be made in two ways:
- Arrays
- Linked lists
Arrays are set spaces in memory for items. Because they all sit in the exact same place, they're easier to get to all at once, but because they're in the exact same place, they're really hard to make larger. An array looks something like this:
A List of Things Not Worth Crying Over:
| Index | 0 | 1 | 2 | 3 |
| Element | Spilled milk | Baseball | It being over | Crying |
To access an array, you'll usually use language like this:
an_array[index]
Linked lists are like chain mail. Each item has two parts: the actual value you want to store in the list, and the link to the next element in the list. Because the elements sit in different places, they're easier to grow. But because they sit in different places, it's harder to access elements in the middle of a list.
They look something like this:
A List of Lists
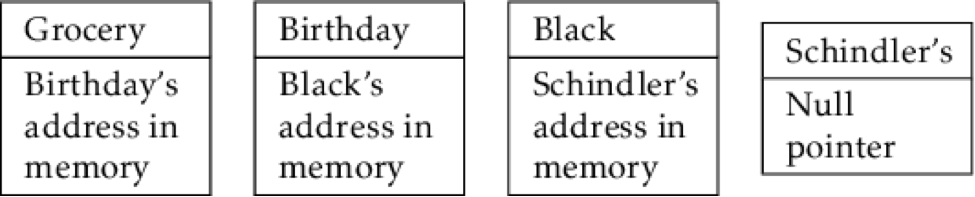
The very last node—Schindler's List—has the link set to null because it's the end of the list.
In this list, we only keep the links to the next node, meaning it's impossible to go backward: we can only move forward. Because of this fact, another related data structure was developed: a doubly-linked list. In the doubly-linked list, each node has two links: one to the next node, and another to the previous node. That way, we can go backwards and forwards forever.
Linked Lists are better than arrays because they don't have a fixed size. Any time you want to add an item, all you need to do is hook it up to the last one. An array, in contrast, makes you copy everything over into a new array with a length one element larger. Yeah, that's really annoying.
Then again, if you want to remove something from a linked list, you can run into a lot of issues with keeping track of the different elements the removed element's attached to. In order to remove an item, you need to
- take the nodes pointing to it.
- change the pointers so that they're pointing to each other.
- remove the node from memory.
Linked lists seem like the clear victor here, no? Not really. If you spend a lot of time finding elements in a list, you'll have to travel possibly to the end of the linked list when you could just take the index of an array. So it really only matters what you need to use the list for.
Queues
Queues are basically specialized lists that let the first element out every time something's removed. They're like the line at the grocery store. The checkout person could signal to random people in line if they wanted to, but they don't. Primarily because the person at the front has probably been waiting the longest and could punch the person who skips, but also because that's the way queues work: you enter at the back and you exit at the front.
When a new person wants to join the queue, that’s an addition. Where does that person go and stand? Usually not the front (unless they're a gambler and want to see if social niceties keep people from pulling out their pitchforks). To make sure polite society remains polite, the person usually joins the queue at the end.
Once a person is checked out, they can leave. What decides the next person to get checked out? You guessed it: the front of the queue. When you put this particular addition with the particular removal together—first element in is also the first one out—the list is called a FIFO (First In First Out).
How you can access the different parts of a queue depends on the language. Since it's implemented using either a linked list or an array, the name of the functions depends on the developer who wrote it.
Stacks
Some lists don't have the same social conventions as queues, so we don't need to worry about angry mobs.
Say you're going to have a party. We know the first thing you tend to think about: plates.
No? Okay, well humor us.
You have enough plates to serve everyone and no one cares which plate they get. Yes, we know this isn't always the case. But this time, all the plates are the same. So you put the plates in a stack. Unlike a queue, it doesn't matter which plate was placed first: the last one's always grabbed first.
Unless you like broken china, that is.
Just like in life, the stacks in computer science are Last In, First Out (LIFO). They might not sound that important, but stacks can be very helpful depending on the algorithm. It really depends on how you need to access the information.
Again, the functions you need to call to get elements from a stack are different depending on the language, but all most all of them use the function
pop()
to take off the last element from a list. Because…you're popping it off the top.
2D Arrays
We've talked about single arrays in the form of lists; we've even talked about structures built on the idea of single dimensional arrays. Now we're going to hop dimensions. Say you want to do something crazy like
- have an image show up on a computer screen.
- represent a theater seating chart.
- classify emojis by color and facial expression.
You're going to want an easy way to classify and get to specific places on a gridlike pattern. In most languages, an 2-D Array will look like this:
an_array[row][column]
for whichever piece of data you need. Most languages also just think of them as arrays of arrays, but you won't have to think of them that way outside of, y'know, creating them.
Now, the arrays can hold objects and arrays are…objects. So…the multi-dimensional ‘array’ is constructed as an array of arrays. Let’s look at the case of a matrix of size n * m (n rows and m columns). First you declare the array of size n, then you fill each place in the array with an array of length m.
That's it.
Or, if images are more your thing:
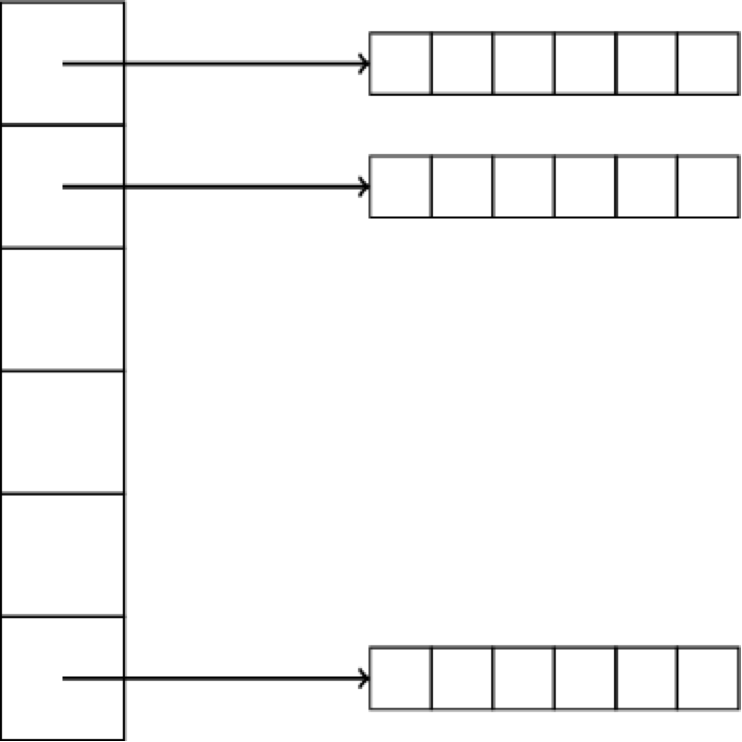
To assign a value to each element, you will need as many for loops as the dimensions of the array. Yes, we can go bigger than two dimensions, but with great array power comes great array responsibility. When you're first starting out, it might be easier just to limit yourself to three dimensions, because…that's what we have in the real world—or at least it's what we can sense.
Dictionary
And now for something completely different.
Dictionaries come in many different names. You could even create a dictionary of dictionary names. It'd be a very efficient use of both computer memory and your time. If you hear someone talking about a(n)
- associative array
- map
- hash table
- hash
in computer science, they're talking about a dictionary (most of the time). A dictionary element has two parts: the key and the value. The value is the actual piece of data and the key is how you find it.
Say you're the ex-spy protagonist in a gritty action movie set in Switzerland. As any ex-spy, you have a Swiss Bank Account that holds all your ex-spy gear, just waiting for the day when your nemesis goads you out of retirement. But until then, you just have the key to that vault. Use the key and you have instant access to your spy equipment (and revenge).
In computer science, a dictionary is just like that Swiss Bank Account. In order to get to the value, you need to have the key. The key is just a variable that points to the value in memory. Accessing the information is a lot quicker than in an array, so you can get your spy revenge quicker.
The key is a unique identifier of value and you need it to find the value. The value could be any thing, including the different data structures (maybe even another dictionary).
Since the key's a unique identifier for the value, setting the value for a key already matched with a value might have side effects. Some programming languages might not like that and throw an exception. Some programming languages may just choose to overwrite the value for that key. Either way, you probably want to avoid doing it.
Actually putting the value in memory is a little complicated, but we don't need to talk about that right now.